 Dummy Variable / 더미변수 / 가변수
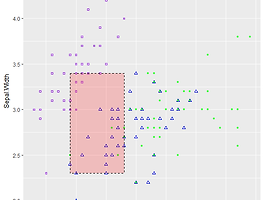
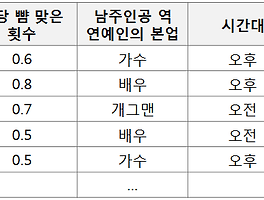
Dummy Variable / 더미변수 / 가변수 포스팅을 읽어주신 고마운 분과 댓글로 질의응답을 하다가 간단한 내용이니 포스팅 해봐야겠다 생각해서 급하게 글을 쓰고 있다. (1) 더미변수란?(2) 더미변수는 왜 만드나?(3) 더미변수의 특징(4) 더미변수로 변환하는 법(5) 더미변수의 의미 (1) 더미변수란? 더미변수는 범주형 변수를 연속형 변수로 변환한 것인데, 정확히 따지자면 연속형 변수"스럽게" 만든 것이다. -연속형 변수숫자로 이루어져 있으며, 끊키는 부분 없이 연속적으로 값을 가질 수 있다.예를 들면 키, 몸무게, 온도, 나이, 고객수, 구매율 등 범주형 변수문자 또는 숫자로 이루어져 있으며, 범주(카테고리)가 있다.예를 들면 학년(1, 2, 3), 혈액형(A, B, O, AB), 성별(남, ..
Dummy Variable / 더미변수 / 가변수
Dummy Variable / 더미변수 / 가변수 포스팅을 읽어주신 고마운 분과 댓글로 질의응답을 하다가 간단한 내용이니 포스팅 해봐야겠다 생각해서 급하게 글을 쓰고 있다. (1) 더미변수란?(2) 더미변수는 왜 만드나?(3) 더미변수의 특징(4) 더미변수로 변환하는 법(5) 더미변수의 의미 (1) 더미변수란? 더미변수는 범주형 변수를 연속형 변수로 변환한 것인데, 정확히 따지자면 연속형 변수"스럽게" 만든 것이다. -연속형 변수숫자로 이루어져 있으며, 끊키는 부분 없이 연속적으로 값을 가질 수 있다.예를 들면 키, 몸무게, 온도, 나이, 고객수, 구매율 등 범주형 변수문자 또는 숫자로 이루어져 있으며, 범주(카테고리)가 있다.예를 들면 학년(1, 2, 3), 혈액형(A, B, O, AB), 성별(남, ..